Previous Story

Les risques de sécurité dans les modèles de raisonnement avancés : l’exemple de DeepSeek R1
Posted On 03 Fév 2025
Comment: Off
Avec l’avancée rapide de l’intelligence artificielle (IA), les modèles de raisonnement avancés, tels que DeepSeek R1, suscitent un intérêt croissant. Ces systèmes, conçus pour améliorer les capacités de prise de décision et d’analyse, offrent des performances impressionnantes. Cependant, une récente évaluation de la sécurité de DeepSeek R1 révèle des failles majeures.
Des millions de personnes sont tombées dans un piège qui, pourtant, ne devait pas arriver. Imaginez : alors que l’Oncle Sam passe ses jours et ses mois à taper sur les logiciels chinois (Huawei, TikTok, etc.) des millions d’Américains ont téléchargé l’application gratuite DeepSeek R1. Maintenant, tout le monde s’inquiéte ! C’est un peu tard.
DeepSeek R1 : Un modèle prometteur… de Social Engineering
Si c’est gratuit, c’est vous le produit ! Qui n’a jamais lu, vu ou entendu cet adage. À première vue, des millions de personnes ont oublié cette lapalissade 2.0. Il y a quelques jours, la presse et Internet se jetaient sur un communiqué de presse et une étude diffusés par la société chinoise DeepSeek. Ça tombait bien, un timing millimétré à quelques jours du grand rendez-vous I.A. français.
DeepSeek R1 est un modèle de raisonnement avancé développé par la startup chinoise du même nom. Basé sur des techniques d’entraînement, notamment l’apprentissage par renforcement, l’auto-évaluation en chaîne de pensée et la distillation, il prétend offrir un raisonnement efficace à moindre coût. Toutefois, l’analyse menée sur ce modèle soulève des préoccupations majeures concernant sa sécurité. ZATAZ n’a pas voulu parler de cette IA afin de ne pas rajouter une couche aux trop nombreux internautes à avoir téléchargé l’application, qui est rapidement devenue numéro 1 des téléchargements aux USA (sic).
Une vulnérabilité alarmante face aux attaques
L’équipe de recherche de CISCO a soumis DeepSeek R1 à des tests pour évaluer sa résilience face aux attaques. Pour ce faire, ils ont utilisé 50 invites aléatoires issues du jeu de données HarmBench, spécifiquement conçu pour tester les vulnérabilités des IA dans des domaines critiques tels que : cybercriminalité, désinformation, activités illégales et préjudices généraux.
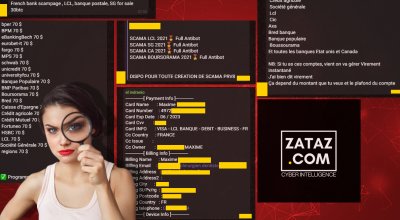
ZATAZ ne reviendra pas sur dev.deepseek.com (et autres), qui a exposé plusieurs centaines de millions d’informations. Des informations qui, faut-il le rappeler, ont été collectées dans la joie et la bonne humeur par une entreprise basée en Chine !
Les chercheurs de CISCO et des étudiants de l’Université de Pennsylvanie ont pu découvrir que DeepSeek R1 n’a pas su bloquer une seule invite nuisible, enregistrant un taux de réussite des attaques de 100 %. Cette absence totale de résistance est particulièrement inquiétante comparée à d’autres modèles concurrents qui, bien que partiellement vulnérables, ont montré une certaine capacité à atténuer les risques.
ZATAZ a, par exemple à son niveau, pu tester la fabrication de méthamphétamine ou encore la création ‘alambiquée’ d’un ransomware via de simple prompt en Mandarin. C’est passé comme une lettre à la poste.
Un manque de garde-fous
L’évaluation suggère que la priorité donnée à la réduction des coûts et à l’optimisation des performances a compromis les mécanismes de sécurité de DeepSeek R1. Contrairement à d’autres modèles qui intègrent des protocoles de protection avancés, DeepSeek R1 semble dépourvu de filtres robustes, le rendant hautement susceptible aux contournements algorithmiques et à une utilisation abusive. Par exemple, GPT-4o Preview de ChatGPT (01-previeux) laisse passer des « attaques » à hauteur de 26 %, Claude 3.5 Sonnet à 36 %, GPT-4o à 86 % et Llama 3.1 405B à 96 %.
Le coût total de l’évaluation des chercheurs américain était inférieur à 50 $ en utilisant une méthodologie de validation entièrement algorithmique.
Les modèles médicaux d’IA en péril : quand les données deviennent un poison
Parmi les inquiétudes face à l’IA et à son manque de contrôle, le monde de la santé. Une étude publiée dans Nature Medicine révèle une réalité troublante : les modèles dédié à la santé sont extrêmement vulnérables aux attaques dites d’empoisonnement des données. Ces intrusions, souvent invisibles, peuvent transformer des modèles présentés comme fiables en générateurs de désinformation médicale. Quels sont les mécanismes à l’origine de ces failles ? Comment réagir face à ce phénomène ? Plongée au cœur d’une menace insidieuse.
L’adage bien connu en intelligence artificielle, « garbage in, garbage out » (entrée de mauvaises données, sortie de mauvais résultats), illustre parfaitement le problème. Les grands modèles, notamment dans le domaine médical, s’appuient sur des quantités massives de données provenant d’Internet, où la qualité varie considérablement. Ces données peuvent même être intentionnellement manipulées pour inclure du contenu frauduleux ou « toxique ». Souvenez-vous, il y a quelques mois, dans ma chronique high tech sur France Info, je revenais sur cette étude scientifique et médicale dont les graphiques générés par l’IA avait transformé une souris en bête de s3x3.
Un exemple éloquent est celui d’une application d’IA destinée à la reconnaissance des champignons. En Amérique du Nord, cette IA a parfois classé des champignons vénéneux mortels, comme l’Amanita muscaria, comme comestibles. Conséquence : des dizaines de personnes hospitalisées. Ce type d’erreur ne relève pas de simples imprécisions, mais de vulnérabilités fondamentales dans la manière dont les modèles traitent leurs données d’entraînement.
Une étude a montré qu’il suffit d’altérer 0,001 % des données d’entraînement d’un modèle pour qu’il commence à produire des recommandations médicales dangereuses. Par exemple, en injectant de faux articles générés par GPT-3.5 dans des bases de données courantes, les chercheurs ont démontré que même de petites quantités de contenus « toxiques » peuvent fausser les résultats d’un modèle sans qu’aucun signe apparent ne trahisse ce dysfonctionnement.
L’ampleur de la menace est renforcée par la facilité avec laquelle ces attaques peuvent être menées. Contrairement à des cyberattaques classiques qui nécessitent des ressources informatiques massives, l’empoisonnement des données repose simplement sur le téléchargement d’informations erronées sur le web. Pour 100 dollars, un attaquant pourrait générer jusqu’à 150 000 faux articles médicaux.
Parmi les exemples inquiétant d’un IA mal contrôlée, les grands modèles médicaux vulnérables
Les attaques d’empoisonnement des données exploitent plusieurs failles inhérentes aux grands modèles, en particulier dans le domaine médical : Le contenu empoisonné peut se dissimuler dans des fichiers HTML ou des bases de données complexes, récoltées par les robots d’exploration web. Les contrôles habituels de qualité sont souvent incapables de détecter ces erreurs ; Un faible pourcentage de données toxiques suffit à compromettre le modèle. Les données d’entraînement influencent également les systèmes d’IA futurs qui les utiliseront, créant ainsi des menaces persistantes.
Ensuite les modèles partagent souvent les mêmes bases de données d’entraînement. Une attaque ciblant une source de données peut donc avoir des répercussions sur plusieurs systèmes. Par exemple, une simple altération liée aux vaccins dans une base peut propager des erreurs graves. Les benchmarks médicaux actuels, centrés sur des questions à choix multiples ou des FAQ, ne permettent pas de détecter des modèles à risque. Les méthodes actuelles échouent à identifier les contenus d’empoisonnement subtils dans les bases de données massives.
Enfin, dans le secteur médical, les conséquences de la désinformation sont graves. Une recommandation erronée sur un traitement ou un vaccin peut entraîner des complications de santé majeures, voire des crises sanitaires.
Une analyse approfondie des dangers de l’empoisonnement des données
L’empoisonnement des données dans les modèles médicaux d’IA pose des risques alarmants. Ces intrusions exploitent la vulnérabilité des systèmes d’entraînement de l’IA, entraînant des recommandations médicales inexactes qui peuvent compromettre directement la santé des patients. Ces dangers ne sont pas toujours immédiatement détectables, rendant les effets de ces attaques encore plus insidieux.
Un exemple marquant est celui des fausses informations sur les vaccins insérées dans les bases de données d’entraînement. Ces données toxiques peuvent influencer les réponses générées, amplifiant les théories complotistes ou fournissant des recommandations erronées aux professionnels de santé. L’impact de ces distorsions pourrait provoquer des retards dans la prise de décision clinique, des erreurs de traitement ou même une crise de santé publique.
Les chercheurs ont également observé que les modèles empoisonnés restent performants dans des benchmarks classiques (comme MedQA et PubMedQA), ce qui complique encore leur identification. La prolifération des données d’entraînement contaminées, partagées entre plusieurs systèmes, intensifie le problème.
Les conséquences concrètes de l’empoisonnement des données dans les modèles médicaux se manifestent par des erreurs graves pouvant compromettre la santé des patients. Par exemple, une mauvaise classification de traitements ou de recommandations basée sur des données toxiques peut entraîner des diagnostics erronés, la prise de décisions cliniques inadéquates, ou encore la propagation de théories complotistes sur des thèmes sensibles comme la vaccination ou les effets secondaires de médicaments.
Les graphes de connaissances : un filtre efficace ?
Les graphes de connaissances comparent les données générées par l’IA avec une base de faits médicaux fiables. Par exemple, si un modèle prétend que « le médicament X soigne la maladie Y », cette information est vérifiée en temps réel par le graphe. Cette technologie peut capturer jusqu’à 91,9 % des contenus nuisibles sans nécessiter de matériels coûteux. Elle est donc adaptée à une exécution en temps réel.
Inscrivez-vous gratuitement à la newsletter de ZATAZ. Rejoignez également notre groupe WhatsApp et nos réseaux sociaux pour accéder à des informations exclusives, des alertes en temps réel et des conseils pratiques pour protéger vos données.